

データベースの内部構造を知ろう入門以前(PostgreSQL編)

この記事は リクルート プロダクトデザイン室 アドベントカレンダー 2022 16日目です。
私は普段、『Airペイ』・『Airペイ QR』をはじめとした決済サービスや、『Air ビジネスツールズ』(https://www.recruit.co.jp/blog/service/20201124_169.html)と呼ばれる業務支援のための各サービスで利用する業務共通機能基盤のPdMをしています。
複数のシステムの開発・運用を日々している中で、時には不具合や障害も発生します。原因は様々ですが、PdMであっても一定技術的な知識を持っておくことで、
自身でも問題の想定箇所の当たりを一定つけることができる
インフラエンジニア、アプリケーションエンジニアの方々と共通言語で会話ができる
と、対処がスムーズに進むということを実感しています。
PdMであっても技術的な知見を生かして仕事をしている方は一定おり、今回はその様子の一端を知って頂きたくアドベントカレンダーを執筆しました。
身につけておくべき知識はアプリケーション、ミドルウェア、インフラレイヤなど多岐に渡りますが、今回はPostgreSQLを題材にデータベースの内部構造についての入門以前的な内容を取り上げてみたいと思います。
(技術用語が適宜登場しますが、必要に応じて調べつつ読み進めてもらえると助かります)
PostgreSQLとは?
PostgreSQLは、オープンソースとして開発されているリレーショナルデータベースのことです。日本では昔から積極的に利用されているデータベースの一つで、ユーザ会の活動も活発な印象があります(https://www.postgresql.jp/)。また大変有り難いことにドキュメントの翻訳もユーザ会の方が中心となって対応されており、日本語のドキュメントも多くあります。
読み方は「ぽすとぐれすきゅーえる」と読みます。一般的には「ポスグレ」と呼ばれることが多いです。
私の担当するプロダクトでは、基幹系システムでは商用のリレーショナルデータベースを利用することも多いですが、
一部においてPostgreSQLのようなオープンソースのデータベースを活用している箇所もあります。
PostgreSQLのプロセス構成
PostgreSQLを起動すると、複数のプロセスがOS上に立ち上がります。(プロセスとはプログラムの実行単位のことです)
試しに起動直後のプロセスを確認すると、以下が表示されました。

PostgreSQLでは多くのプロセスが互いに動作をしながら、リレーショナルデータベースとして必要な処理を行っていく構成となっています。一部のプロセスについてはこのあと取り上げて簡単に説明します。
クライアントからSQLを実行し、トランザクションを完了するまで
クライアントからPostgreSQLに接続し、SQL実行したうえでトランザクションを完了させる際の一連の流れについて、以下の図に概要をまとめました。
順を追って説明していきます。
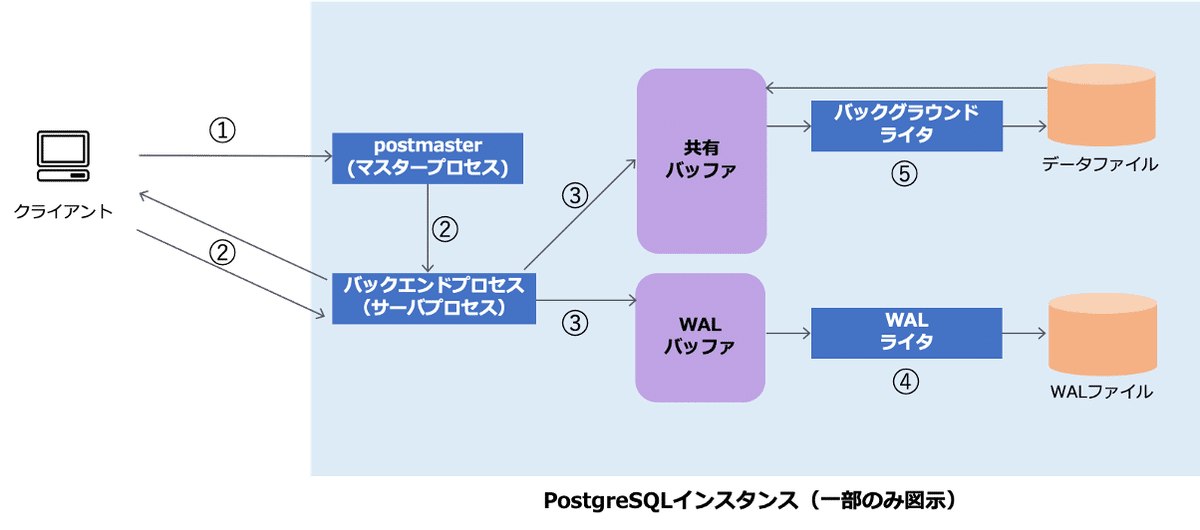
①クライアントからPostgreSQLへ接続
PostgreSQLは起動後、postmaster(マスタープロセス)と呼ばれるプロセスがクライアントからの接続を受け付けます。リスナープロセスとも呼ばれます。
(PostgreSQLの場合、ポートは5432ポートを利用することが多いと思います)
ここで言うクライアントとは、PostgreSQLを利用するクライアントアプリケーションのことを指します。
PostgreSQLに接続を試みるクライアントは、postmasterが待ち受けるIPとポートに対して接続を行います。クライアントから接続を受けたpostmasterは、認証情報の確認などを実施したのちに②のバックエンドプロセスのforkを実施します。
②バックエンドプロセスのforkと通信経路の確立
postmasterはクライアントからの接続を受け付けると、新たにプロセスをforkします。このプロセスはバックエンドプロセス(サーバプロセス)と呼ばれ、クライアント毎にforkされるものです。
以降のクライアントとの通信は、クライアントとバックエンドプロセス間で通信経路を確立して行われます。
③クエリの実行
クライアントからバックエンドプロセスに対してクエリ情報が送信されると、バックエンドプロセスにて構文解析などが行われたのちに実行計画が作成され、処理が行われます。
結果は共有バッファに反映されますが、この時点ではまだデータファイルへの書き込みは行われません。
また、データ更新結果はWALバッファと呼ばれるメモリ領域に格納されます。(WALバッファのデータ永続化については後述します)
共有バッファには、テーブルのデータがキャッシュされて格納されています。バックエンドプロセスからはこのキャッシュされたデータを参照することによってファイルへのアクセスを減らすことができ処理を高速化することができます。
④トランザクションログ(WALログ)の書き込み
クエリの実行によるデータ更新結果はWALバッファと呼ばれるメモリ領域に格納されます。
COMMIT文実行によるトランザクションの終了時などのタイミングで、WALバッファ上のデータはWALログと呼ばれるファイルに書き出され永続化されます。
このタイミングではWALバッファ上のデータのみがWALログに書き出され、共有バッファに反映されたテーブルデータは永続化されません。
このWALログは万が一の障害・トラブル時のデータ復旧に利用することもでき、定期取得しているバックアップデータにこのWALログを適用することでデータベースを最新の状態まで復旧することが可能です。(ポイントインタイムリカバリとも呼ばれます)
⑤共有バッファのデータをデータファイルへ書き込み
共有バッファに反映されたテーブルデータはバックグラウンドライタと呼ばれるプロセスが適宜データファイルへ書き出します。
この処理は④で触れたとおり、クライアントからのCOMMITのタイミングとは同期していません。
以上のように、各ファイルへのデータ書き込み・永続化はそれぞれ別のプロセスが独立して実行しています。
WALファイルへの書き込み:WALライタプロセス
データファイルへの書き込み:バックグラウンドプロセス
PdMとして技術の知見を持つ意味
プロダクトを運用していると、大小含め日々様々なトラブルが発生します。特にデータベース周りで問題が起こることも多いですが、その際にも今回のような知見を持つことでデータベースエンジニアの皆さんとも共通言語で会話ができ、問題の把握や早期解決に役立つことがあると感じています。
おわりに
今回は、PostgreSQLを題材にデータベースの内部動作の概要を簡単に取り上げてみました。PostgreSQLは追記型アーキテクチャという仕様を採用している点や、今回軽く取り上げたポイントインタイムリカバリについてなど、他にも機会があればまたまとめたいと思います。
冒頭でも触れましたが、データベース以外にも多くの技術知識を得ることは大事ですが、それぞれの分野はとても奥が深く、極めることは容易ではありません。
興味を持った分野について、自分のペースで無理なく学習の歩みを進めることが大事なのかなと個人的には思っています。
最後まで読んで頂きありがとうございました!
参考
PostgreSQL文書(日本語版)
PostgreSQLアーキテクチャ入門
PostgreSQLの内部構造―プロセスやメモリの流れ、特徴的な機能のしくみ
PostgreSQL共有バッファと関連ツール
内部構造から学ぶPostgreSQL 設計・運用計画の鉄則
PostgreSQL入門 〜アーキテクチャ編〜
